学习 React JS 相关总结
写在前面:
最近在写前端,感觉代码在页面不断堆积,以后维护和扩展也是一件头疼的事,对于做过几年后端开发的我来说,不合理的代码组织就像乱糟糟的房间一样看的难受,现在有必要学习这个框架了.
学习链接: 认识 React
写了一些 demo,随后集中整理一下

写在前面:
最近在写前端,感觉代码在页面不断堆积,以后维护和扩展也是一件头疼的事,对于做过几年后端开发的我来说,不合理的代码组织就像乱糟糟的房间一样看的难受,现在有必要学习这个框架了.


The multiprocessing library gives each process its own Python interpreter and each their own GIL(Global Interpreter Lock).
allows you to create programs that can run concurrently (bypassing the GIL)
use the entirety of your CPU core
import multiprocessing
def concurrent_multi_process():
dids = []
with concurrent.futures.ProcessPoolExecutor() as executor:
results = executor.map(call_out_data, dids)
def call_out_data(did):
requests.adapters.DEFAULT_RETRIES = 5
url = "http://202.205.91.21:60001/nrmv/canInfo"
headers = {
'Content-Type': 'application/json'
}
payload = json.dumps(
{
'appId': "",
"did": did,
"startTime": 'test',
"endTime": '20220610000000',
"limit": 1000000000,
"nextPageStartRowKey": "",
"reverse": 'false',
"showColumns": ["`did`", "`3014`", "`2602`", "`2603`", "`2204`"],
"token": ""
})
response = requests.request("POST", url, headers=headers, data=payload)
print(response)
if (response.status_code == 200 and 'data' in response.json()):
data = response.json()['data']
return data

it’s perfect for I/O operations such as web scraping because the processor is sitting idle waiting for data.
import threading
def thread_process():
dids = []
with concurrent.futures.ThreadPoolExecutor() as executor:
results = executor.map(call_out_data, dids)

pip install XXX
pip3 install XXX
sudo pip3 install XXX
python -m pip install XXX
python3 -m pip install XXX
conda install -c anaconda XXX
sudo pip3 install XXX
If the “No module named ‘XXX’” error persists, try restarting your IDE and development server / script.
You can check if you have the XXX package installed by running the pip show XXX command.
pip3 show XXX
python3 -m pip show XXX
The pip show XXX command will either state that the package is not installed or show a bunch of information about the package, including the location where the package is installed.
If the package is not installed, make sure your IDE is using the correct version of Python.
If you have multiple Python versions installed on your machine, you might have installed the XXX package using the incorrect version or your IDE might be setup to use a different version.
For example, In VSCode, you can press CTRL + Shift + P or (⌘ + Shift + P on Mac) to open the command palette.
Then type “Python select interpreter” in the field.

Your IDE should be using the same version of Python (including the virtual environment) that you are using to install packages from your terminal.
pip3 show XXX
python3 -m pip show XXX
pip3 uninstall XXX
python3 -m pip uninstall XXX
pip3 install XXX
python3 -m pip install XXX
| 破损类型 | 外观描述 | 破损程度 | 换算系数 |
|---|---|---|---|
| 横向裂缝 | 轻:少分支、缝隙小、缝壁无散落; 中:少分支、缝隙较小、缝壁散落轻微; 重:少分支、缝隙较大 |
轻/中/重 | 0.6/0.8/1.0 |
| 纵向裂缝 | 轻:少分支、缝隙小、缝壁无散落; 重:少分支多、缝隙较大、缝壁散落严重 |
轻/重 | 0.2/ 0.4 |
| 网状裂缝 | 轻:缝细、缝壁无散落、变形不明显; 重:网格众多、缝壁散落严重、缝隙较大 |
轻/重 | 0.4/0.6 |
| 块状裂缝 | 轻:缝细、缝壁无散落、块状大; 重:缝宽、缝壁散落严重、块状小 |
轻/重 | 0.2/0.4 |
$$g(x,y)=\frac{Y_{b}-Y_{a}}{X_{b}-X_{a}}\left[f(x,y) - X_{a}\right] + Y_{a}$$
#### 直方图均衡化利用图像直方图对对比度进行调整,在路面裂缝图像中,路面背景与裂缝的对比度相对较为接近。直方图均衡化对图像进行非线性拉伸,重新分配图像像素值,而把给定的直方图分布变成均匀分布的直方图。在相对信息量较大的图像中,通过将图像的对比度增强达到数据图像清晰度增加的目的。该方法较为直观,而且操作具有可逆性,可以恢复原始的直方图。
#### 中值滤波对噪声有良好的滤除作用,能够有效的保护信号的边缘。在路面裂缝图像采集过程中,由于各种各样噪声的影响不仅不利于影响了训练速度的提升也严重干扰了图像的特征提取。中值滤波是基于排序统计理论的一种能有效抑制噪声的非线性信号处理方法,能够很好地抑制图像中的噪声。
#### 形态学图像处理方法可以有效的解决形状识别、抑制噪声、纹理分析、边缘检测、图像压缩等问题,主要以几何结构为基础,且提取的边缘较为光滑,断点少,可以有效的保持原始图像,而能否有效的提取信息的关键在于结构元的选择,结构元的选择必须比原图像要简单并且有边界。路面裂缝图像经过灰度变换、直方图均衡化和中值滤波处理后仍然会存在孤立的噪声点或者细小的裂缝,为了减弱噪声点和细小裂缝对路面图像特征提取的影响需要使用形态学处理方法消除这些噪声点和连接细小裂缝。
[1] MOHAN A, POOBAL S. Crack detection using image processing: a critical review and analysis[J]. Alexandria Engineering Journal
[2] JIANG Ming-hu, GIELEN G, DENG Bei-xing, et al. A fast learning algorithm for time-delay neural networks[J].Information Science,2002,148(1-4):27-39
创建一个 Service 层的 class 并且在应用中高效的使用
暴露出一个用 Service 层做的 API
下面介绍的这个方法展示了使用 service 利用 discount 来建立一组 discount
1 | public with sharing class OpportunitiesService |
主要目标
理解 Martin Fowler 为了做企业级架构而分离出 Service 层的缘由
理解为什么 Apex 代码要属于 Service 层
在应用和平台的开发中如何很好的契合 Service 层的代码
在 salesforce 平台上用代码去实现 Service 的架构
上一篇 Blog 只是简单的介绍了 SOC 思想,将软件的结构抽象到层级应用的逻辑方面,本篇 Blog 主要将目标集中在如何去定义和实现 Service 层,它也是别的层级或者 API 调用的关键步骤。
层级架构之间的关系图:
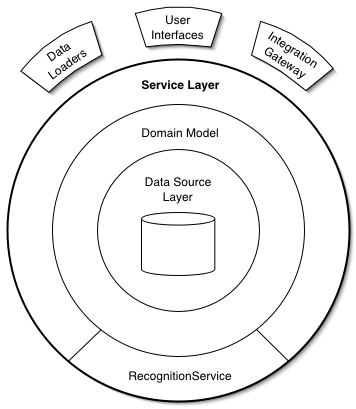
Service 层对实现的业务层、运算层和一些执行业务的逻辑 Process 有一个清晰和严格的封装,同时 service 层必须保证足够的功能专一和抽象,它能够适应后期功能的多次迭代和灵活的可扩展性。下面的内容是如何使用 Apex 代码来实现 Service 层的业务逻辑,同时说明如何在 Force.com 资源有限的情况的下合理的利用资源去实现它。
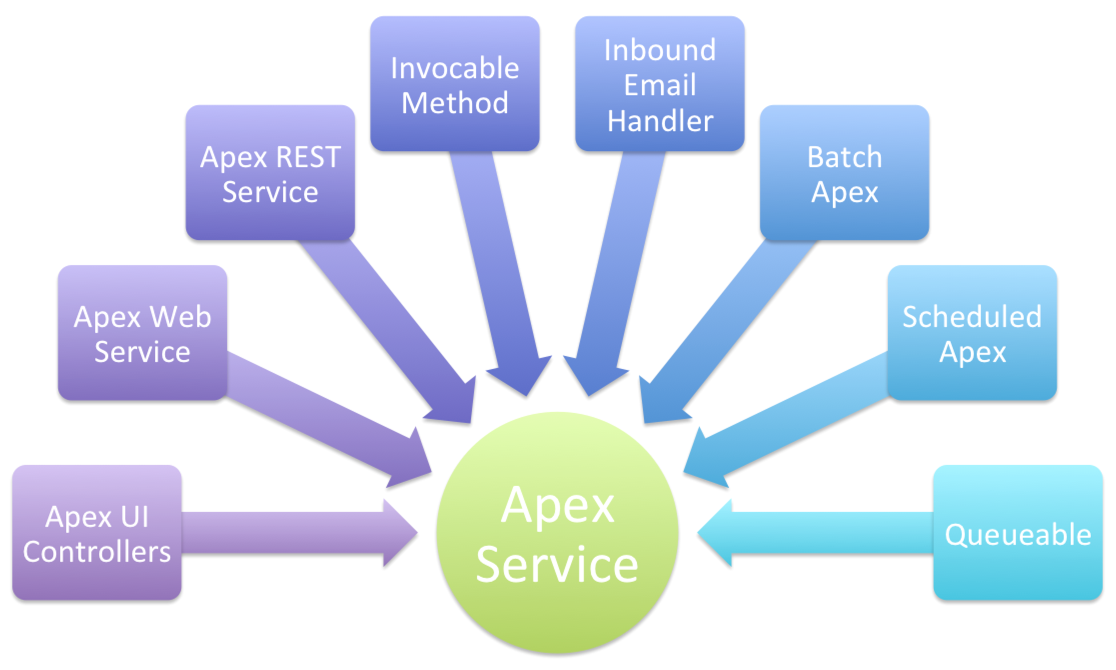
客户端(client)执行 Service 层的业务逻辑,比如像 UI controller 或者 Batch Apex 等。
值得考虑使用 Service 层的一些方向:
1 | 注意: |
想象一下有这么一个场景,当写了一段 feature 代码,需求只要一变就得重新对代码进行重构,或者更糟糕的是由于害怕之前写的逻辑被破坏,索性不敢动之前的逻辑,然后出现了大量的重复的代码,真是很糟糕的体验。
命名规范:Service 层应该足够抽象而且其意义,同时应该很广泛来涵盖客户端的很多情况,这些方面可以表现在对类、方法、参数名的命名规范上,什么时候用动词(verbs),什么时候用名词(nouns)都要有所思考;确保名字所表达的是种一般情况而非特殊情况,举个例子,这个方法名是以业务操作来命名的 InvoiceService.calculateTax(…) ,而第二个方法名是以特定的业务操作来命名的 InvoiceService.handleTaxCodeForACME(…) 应该避像第二种这样的的命名方式
平台 / 协调一致:设计一个签名的算法和 Salesforce 平台进行交互是一个很好的实践,尤其要使用 Bulkificaiton 的时候,一个主要需要考虑的因素是,在所有运行在 Force.com 上的代码都是 Bulkificaiton,要考虑调用服务器端的代码参数数组化,而不是一个单一的参数集,举个例子,这个方法就可以使用 Bulkificaiton => InvoiceService.calculateTax(List
SOC 方面的考究:在应用当中 Service 层的代码利用很多 Objects 封装一些任务或者 Process 业务逻辑,与之相对应的是,有些代码关联着特定的 validation、field values 或者 calculations,通过插入、更新、删除触发Trigger 来影响其相对应 Object, 这些代码一般存放在 Trigger 当中,并且可以保留在那里
安全性:Service 层的代码和那些被调用的代码应该确保用户安全,要确保这一点使用 with sharing(with Security Settings enforced)修饰符,尤其需要注意的是如果使用 global 修饰符暴露了太多关键代码,就需要引起注意。如果一个 Apex 类的逻辑必须通过一些 Recodes 让外部的用户可见,那么代码必须提炼它的执行环境,越简略越好,一个好的办法是使用私有的 Apex 内部类,使用 without sharing
关键字
编组:简言之,避免指定如何处理与 Service 层交互的方面错误信息,因为某些方面最好留给服务的调用者,只管原样抛出异常就好(it is typically best to leverage the default error-handling semantics of Apex by throwing exceptions. )
整合服务:虽然客户端可以一个接一个的执行多次 callout,但这么做会很低效,也会造成一些数据库事务方面的问题,最好的办法是建一个整合服务( compound services)(compound services),让一次 callout 涵盖多个客户端的请求。同样很重要的是尽可能优化 Service 层的 SOQL 和 DML 操作。当然了这并不意味着不能 callout 更细节的逻辑单元;如果需要的话,可以开发特定的单元去以供客户端 callout
事务管理和无状态: Service 层的客户端经常有一些拥有长存活时间且不同的 Process 请求和一些消息用来执行和处理,举个例子,一个单一的请求和多个请求分隔成单独的作用范围到服务器端:管理状态(比如 Batch Apex)或者复杂的 UI 都是通过它们自己的页面状态来接受很多请求的,在状态管理上最好的方式是在做一次 callout 到 Service 层时,封装数据库操作和服务状态。换句话说,使 Service 端保持无状态,以使调用的环境灵活地使用它们自己的状态管理解决方案。例如,一个在数据库事务的作用域同样应该被包括在每一个 Service 层的方法当中,以便于调用者不用去考虑和其相关的 SavePoints
配置:在 Service 层中,可能有常见的配置或行为被覆盖,合理使用方法重载,接受一个共享的选项参数,类似于 Apex 中的 DML 方法
情景介绍:假设在 Opportunity 页面有个自定义 Button 当点击 Button 会出现一个 Visualforce 页面,提示用户对 Opportunity Amount(或相关联的 Opportunity Line)项目应用一个折扣百分比。
实例展示如何将 OpportunitiesService.applyDiscounts 方法应用到比如 Visualforce、Batch Apex、 或者 JavaScript Remoting 这些地方上。
下面的 Code 处理的是通过 StandardController 选择的单个 Opportunity,注意:controller 的错误信息是 controller 自己来处理的,而非 service,因为 visualforce 有其自身的错误表现形式。
1 | public PageReference applyDiscount() |
下面的 Code 展示了通过 StandardSetController 处理多个 Opportunities
1 | public PageReference applyDiscounts() |
下面的 Code 展示了如何使用 Batch Apex 处理大量的数据,注意和之前代码的区别
1 | public with sharing class OpportunityApplyDiscountJob implements Database.Batchable<SObject> |
下面的 Code 将 service 层打包起来,并且通过 JavaScript Remoting 暴露给客户端,供其调用
1 | public class OpportunityController |
在 Service 层提不断投入对更大的重用性和适应性的都带来很大的好处,同时也为应用程序实现 API 提供了一种更干净、更经济的方式之一。
原文:
Investing in a service layer for your application offers the engineering benefits of greater reuse and adaptability, as well as provides a cleaner and more cost effective way of implementing an API for your application, a must in today’s cloud-integrated world. By closely observing the encapsulation and design considerations described above, you start to form a durable core for your application that will endure and remain a solid investment throughout the ever-changing and innovative times ahead!
Separation of concerns
Martin Fowler’s Service Layer Pattern
Martin Fowler’s Enterprise Architecture Patterns
Learn Service Layer Principles
With Sharing、Without Sharing 和 non-sharing-specified 修饰符的区别
解释 SOC 用于商业的价值
在使用一些需求或者平台技术中使用 SOC 来适用一些解决方案
将 SOC 应用到 Force.com 中
什么时候决定使用 SOC 技术
1 | 作为一个 salesforce developer 不能仅仅停留在为客户解决一些业务逻辑方 |
广义上来说SOC是一种分层思想的体现,在大多数OOP语言中都有涉及,这里不再赘述,但需要强调的是,代码的功能模块是可以不断复用的,我们不提倡 copy & paste,但要时刻想着复用,并且类的命名规范(class naming conventions),变量名的命名规范(variable naming conventions)都有助于代码可读性的提升,好的代码如同讲一段优美的故事,That is Good code should tell a story.
1 | salesforce 层级分类如下: |
在 App 中替代或者添加另一种 UI(Replacing or adding another UI to your app),需要考虑的是有多少代码需要去重写,或者有些 UI 的端口虽然什么都没做,但是影响到了 App 的 插入(inserting),更新(updating),验证(validating)或者计算处理(calculating)的一些功能。
提供公用 API(Providing a public-facing API)评估一下所实现的 API 使用已有代码库的哪一部分,不要将一些动作行为的方法作为 API 基础的调用
通过 Batch 类来提升应用层逻辑(Scaling your application logic via Batch Apex)使用 Batch 来增大数据吞吐量,使多个用户在登录相同的 UI 页面的时候有相一致的结果
在 Visualforce 页面或者 Lightning Component controllers 中执行复杂的业务逻辑(Working with complex action methods in your Visualforce or Lightning Component controllers)言简意赅,使用 MVC 架构,很老生常谈的东西,在随后的章节会陆续介绍
让一个新的开发人员能快速上手项目的架构(Making it easy for new developers to find their way around your code base)一个新的开发人员花在熟悉代码组织架构的时间也是衡量一个项目好坏的标准之一
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
1 | $ hexo new "My New Post" |
More info: Writing
1 | $ hexo server |
More info: Server
1 | $ hexo generate |
More info: Generating
1 | $ hexo deploy |
More info: Deployment